
The Senior Engineer Bottleneck: Scaling Through Replacement
Why your team’s inability to do your job is your biggest career failure.

In previous logs, we analyzed the Bus Factor of 1 and the Hero Trap. We established that being indispensable is a risk and that constant “saves” are a sign of systemic failure. If you hold the keys to every critical system, you are not a leader. You are a bottleneck.
You must now move from diagnosis to repair. If you want to advance, you must build a system that functions without your direct intervention. You must build up your team to build up yourself.
Operating Conditions: The High-Utilization Trap
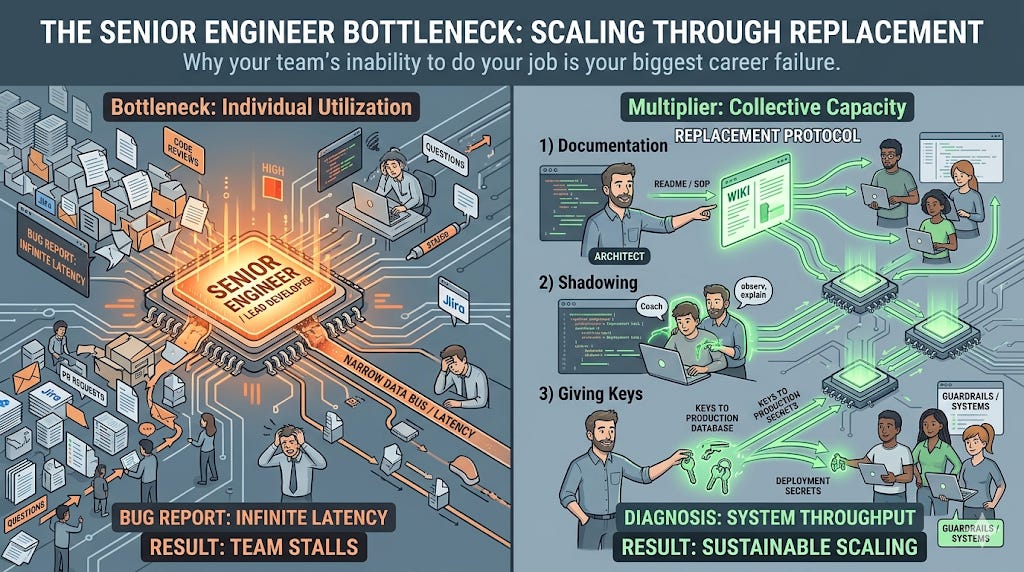
Most senior engineers measure their value by their utilization. They operate at 110% capacity. They attend every architecture meeting. They act as the final reviewer on every critical Pull Request. They think this is high performance. It is actually a sign of poor resource allocation.
In engineering terms, high utilization leads to exponential increases in latency. When a system component is at 100% capacity, any new request, no matter how small, waits in an infinite queue. Consider the Lead Developer who insists on reviewing every line of code. If they are in six hours of meetings a day, the code sits in the queue. The team stalls. Development cycles stretch from days to weeks. You have become the single point of contention in the organizational operating system. Your hard work is actually slowing down the entire cluster.
Failure Modes: The Invisible Foundational Debt
When a senior engineer does all the complex planning and hands off only the execution to the team, a subtle failure occurs. The team becomes a collection of Jira ticket closers. They understand the “what” but not the “how” or the “why.” This is a form of technical and organizational debt.
Take the example of the Sole Release Manager. This person knows exactly which flags to toggle and which services to restart when a deployment goes sideways. They have the internal map of the system’s quirks. Because they “just handle it,” the rest of the team never learns the failure modes. When that manager eventually goes on vacation or gets promoted, the system enters an unrecoverable state during the first minor incident. The team gets credit for delivery during the smooth times, but you are the only one holding the knowledge that prevents total collapse. You feel undervalued because your most critical work, keeping the lights on, is invisible until you stop doing it.
Root Cause: Misunderstanding Your Role as a Component
The “Hero” believes they are a high-performance component. They are the fastest processor in the cluster. But a cluster is only as fast as its slowest link. If you are a 5.0GHz processor connected to the rest of the team via a 10Mbps network, the system-wide throughput is abysmal. Your individual speed is irrelevant if the data cannot move through the rest of the organization.
Your role as a senior is not to be the fastest component. It is to increase the total throughput of the system. This requires a shift in focus from individual output to collective capacity. You are not a component. You are the architecture. If you spend your day squashing bugs that a junior could handle with 20 minutes of training, you are wasting expensive compute cycles. You are optimizing a local variable while the global system is deadlocked.
Proposed Fix: The “Replacement” Protocol
To scale your impact, you must systematically offload your current responsibilities to your team. This is not dumping work. It is strategic capacity building. It requires three distinct phases of execution.
1. Documentation as De-coupling. Stop answering questions in private messages. If a teammate asks how a module works, document it in a shared wiki or a README. You are de-coupling your knowledge from your availability. Your goal is for anyone on the team to find the answer without interrupting your focus. If you have to explain a concept twice, it belongs in a Standard Operating Procedure (SOP).
2. Shadowing and Reverse Shadowing. Stop doing “hard” tasks alone. Bring a junior or mid-level engineer with you. For the first iteration, they watch you. You explain the “why” behind every command. For the second iteration, you watch them. You are the safety net, not the driver. This builds their muscle memory and your confidence in their ability to take over. This is how you eliminate pager load.
3. Relinquishing the Keys. Identify the tasks that only you can do. Hand them over. Completely. If you are the only one with access to the production database or the deployment secrets, you are the bottleneck. Give the team the keys. If you are afraid they will break something, your job is not to hold the keys tighter. It is to fix the system so it is harder to break. Build the guardrails, then step back.
System Status: The Multiplier Effect
True professional value is found in the Multiplier Effect. When you train three engineers to do what you used to do, you have tripled the team’s capacity in that area. You have increased the system’s bus factor and eliminated a primary fire-starting mechanism.
This allows you to move to the next layer of complexity. You can solve problems that require three people instead of one. You are promotable because you have proven you can build systems that scale. You are no longer the bottleneck. You are the architect of a high-throughput organization.
This week’s task: Identify the one critical task that only you can do. Document it. Schedule a reverse-shadowing session. Hand over the keys. If the thought of doing this makes you nervous, you have found exactly where your team needs to grow.
Share Your Stack Traces
I want to see your system logs. Most of you will refuse to admit you are the bottleneck because your ego is tied to being essential. This is a character defect you must resolve. The Request is simple. Tell me about the time your refusal to hand over a process or a secret key caused a total system failure. Provide your telemetry in the comments. We need to document these failures to understand why your team is currently stalled.
System Library: Further Reading
The Book: Staff Engineer: Leadership beyond the management track by Will Larson.
The Engineering Angle: Larson outlines how to transition from executing isolated functions to architecting the operational capacity of the broader engineering organization.
The Concept: Little’s Law
The Logic: This theorem explains why operating at full utilization guarantees that your review queue will infinitely block downstream processes.
The Article: Maker’s Schedule, Manager’s Schedule by Paul Graham.
Why It Matters: Graham defines the context-switching latency that occurs when an engineer is constantly interrupted by dependencies.
The Video: Scaling Yourself by Scott Hanselman.
The Gist: Hanselman examines the failure modes of human bandwidth limits. He diagnoses the individual developer as a local maximum and offers protocols for distributing your processing power.
System Status: Critical?
Writing about management is theory. Fixing it is engineering.
If your organization is suffering from high latency, packet loss in communication, or structural debt, I provide Strategic Debugging and Leadership Mentoring.
I refactor your team like you refactor your code.
Review my operating parameters at weivco.com.