
Throughput Engineering: Your Capacity is Fixed
Your brain is not a server farm. Stop pretending it is.

Operating Conditions: The Myth of Infinite Bandwidth
Organizations operate under a delusional premise: human capacity is infinite. Management allocates tasks as if engineers possess unbounded processing power and zero I/O contention. This is a fundamental miscalculation. You and your team function as a finite system with strict throughput limits.
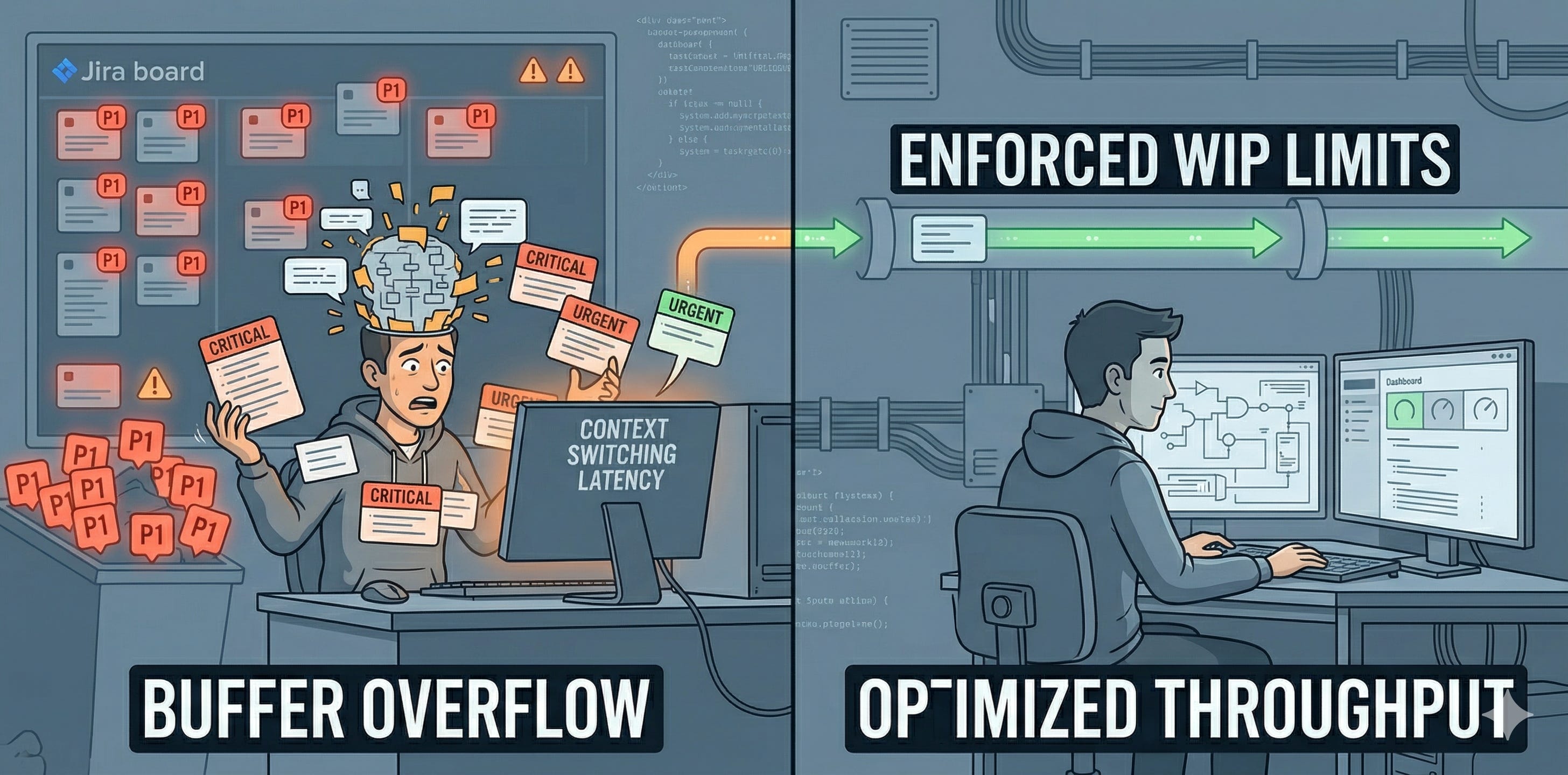
Consider the standard corporate failure mode. A project manager assigns five “critical” initiatives to a single engineering lead. Each requires deep focus, architectural design, and cross-functional coordination. The expectation is not that these will be prioritized sequentially. The expectation is that all five will advance concurrently. This is not bandwidth management. This is a buffer overflow. Inputs exceed processing capacity. The system does not degrade gracefully. It begins to crash.
Failure Mode: Context Switching Overhead is Latency
The human brain, much like a single-threaded CPU, incurs massive overhead when switching tasks. This is not “multitasking.” It is rapid context switching. Each switch demands reloading mental state, recalling specific project details, and re-establishing the problem domain. In economic terms, this cost is pure latency.
Observe a developer attempting to juggle three distinct codebases. Every 15 minutes, an “urgent” Slack message arrives. One is about a production incident on Project A. Another is a design review for Project B. The third is a data request for Project C. Each interruption forces a complete mental stack reset. The developer spends more time on context switching and cache invalidation than on actual productive work. Throughput plummets to near zero. Critical tasks remain incomplete, not because of incompetence, but because the operational environment imposes an impossible latency burden.
Root Cause: Unmanaged Input Queues
The problem of an unmanaged workload stems from a total lack of disciplined I/O protocols. Work arrives in an undifferentiated stream, often with every item labeled “High Priority.” When everything is critical, nothing is critical. This is a signal-to-noise ratio problem. The input queue is a dumpster fire.
Picture a team’s Jira board. It holds 200 open tickets. Every single one is marked “P1 - Critical.” There is no filtering. No intake process. No one actively manages this queue. New requests are simply appended. This is not a backlog. It is a black hole. Engineers pull tasks arbitrarily, usually based on who is shouting the loudest at that moment. This leads to race conditions where multiple engineers unknowingly work on the same dependencies, or worse, duplicate efforts. The system is operating without a clear I/O protocol, leading to packet loss and corrupted signals. Important work gets buried, or never starts.
Proposed Fix: Enforcing Strict Throughput Limits
The solution is not to “try harder” or “be more productive.” That is fairy tale logic. The solution is systemic: enforce strict throughput limits. Treat your capacity as a finite resource. Implement Work-In-Progress (WIP) limits. These are not suggestions. They are operational constraints.
For an individual, this means no more than one or two active tasks at any given time. For a team, it means a hard limit on the number of concurrent projects. If a new “critical” item arrives, an existing “critical” item must be explicitly paused or killed. This forces a real conversation about priority, rather than a fantasy assumption of infinite capacity. You must establish a clear I/O protocol: define the input buffer size, and control the flow.
Actionable Takeaway
This week, conduct a system audit. Identify your current active Work-In-Progress. Everything you are currently touching. Calculate the total. Now, cut that number by 50%.
For every task you cut, explicitly communicate its new status to stakeholders: paused, delayed, or de-prioritized. Defend this boundary. No exceptions.
Share Your Stack Traces
I want to see your system logs. What is the most absurd number of concurrent “P1” tasks you have been assigned? How many context switches did it take to crash your productivity for the day? Post your telemetry in the comments so we can analyze the systemic failures.
System Library: Further Reading
Tools for bottleneck management and I/O optimization.
The Book: The Goal: A Process of Ongoing Improvement by Eliyahu M. Goldratt
The Engineering Angle: The definitive spec on bottleneck management. It treats the organization as a purely physical system. If you do not understand constraints, you are the constraint.
The Concept: Little’s Law
The Logic: The mathematical proof that increasing Work-In-Progress (WIP) directly increases lead time (latency). You cannot argue with the math. Stop pushing inputs when the queue is full.
The Video: Jocko Willink: Prioritize and Execute
The Engineering Angle: This video is a combat logic manual for filtering input noise. It treats attention
System Status: Critical?
Writing about management is theory. Fixing it is engineering.
If your organization is suffering from high latency, packet loss in communication, or structural debt, I provide Strategic Debugging and Leadership Mentoring.
I refactor your team like you refactor your code.
Review my operating parameters at weivco.com.